
While supervised machine learning learns from labeled examples, unsupervised learning analyzes unlabeled data to find patterns. Supervised machine learning techniques are precise but depend on labeled datasets, whereas unsupervised learning is flexible and effective for exploratory analysis. Semi-supervised learning bridges the gap by combining elements of both.
Unsupervised Machine Learning
Unsupervised machine learning is a type of machine learning that helps computers make sense of data without being explicitly told what to look for. In our increasingly data-driven world, this branch of artificial intelligence is playing a growing role in understanding complex datasets, discovering hidden patterns, and aiding decision-making. Its applications affect everyday experiences like personalized recommendations, fraud detection, and even real-time language translation.
What is unsupervised machine learning, exactly?
Machine learning is a branch of artificial intelligence (AI) that allows computers to analyze data, identify patterns, and make decisions or predictions without being explicitly programmed for every task. Essentially, this AI technology teaches computers to learn from examples and adapt over time as they process more data. Supervised and unsupervised learning are two main approaches to machine learning, each with distinct characteristics. In supervised machine learning, a model is trained on labeled data, meaning the input data comes with the corresponding correct outputs. The model learns to map inputs to outputs by minimizing errors during training, enabling it to make predictions or decisions on new, unseen data.
In unsupervised machine learning, the process is slightly different because there are no labels or predefined outcomes for the computer to learn from. The computer is given a set of unlabeled data — the data doesn’t come with explanations or categories. The goal is for the computer to analyze this data and figure out relationships, patterns, or groupings on its own.
For example, imagine you’re organizing a box of photos without knowing anything about the people or events in them. Instead of sorting them based on labels like “Family” or “Vacation,” you might group them based on visible patterns like color, location, or the people who appear in the photos. Similarly, in unsupervised machine learning, computers analyze raw data to find hidden patterns or meaningful structures without human guidance.
How unsupervised machine learning works
Unsupervised learning relies on unsupervised machine learning algorithms to analyze training data and uncover hidden patterns or structures within it. This process allows the computer to find meaningful insights in the data without human-labeled outcomes or instructions. Here’s how the process works:
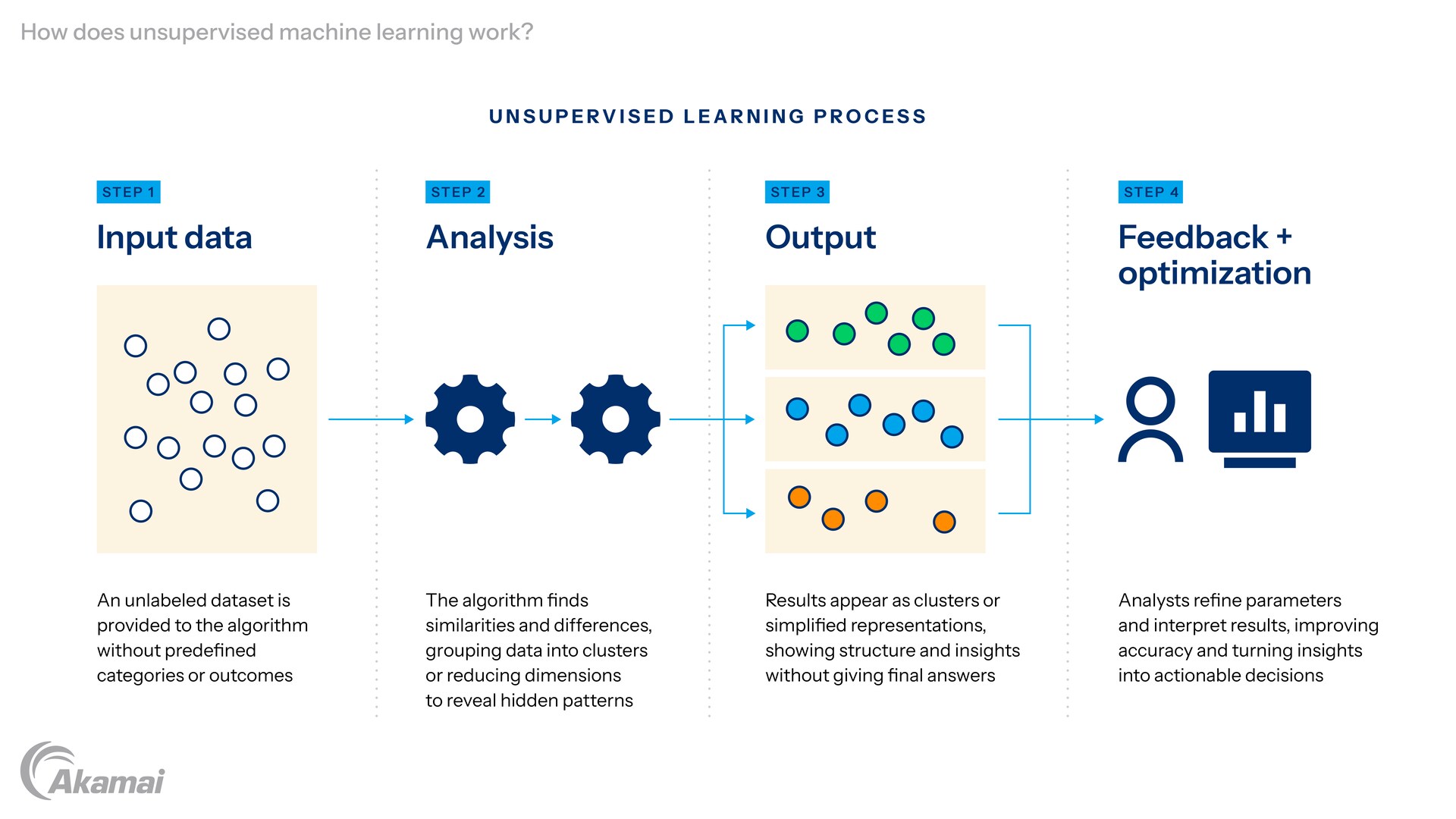
- Input data: The process starts by providing a dataset to the algorithm. This dataset can include various types of data, such as numerical values, images, or text. Importantly, this data is unlabeled, meaning there are no predefined categories, classifications, or outcomes assigned to the individual data points. For example, in a dataset of photos, the algorithm doesn’t know if the pictures are of landscapes, people, or animals — it simply analyzes the raw content.
- Analysis: Once the input data is loaded, the algorithm begins examining the individual data points to uncover relationships, patterns, and structures. It identifies similarities and differences between data points, which helps group them into logical clusters or identify patterns based on shared characteristics. Unsupervised learning algorithms can also identify features within the data to facilitate clustering and dimensionality reduction. These groupings are determined by attributes, such as the number of features (e.g., color, size, or texture) or metrics like distance, which measure how close or far apart the data points are in a multidimensional space. For instance, in a customer database, the data analysis algorithm might group customers with similar purchase histories, even though no labels like “frequent buyer” or “occasional shopper” exist in the data.
- Output: After analyzing the data, the algorithm generates results. These results typically come in the form of clusters, rules, or compressed representations of the data. In a clustering task, for example, the algorithm might divide customers into distinct groups based on their spending habits.The algorithm can group data, revealing data groupings that help businesses better understand their customers. Alternatively, in dimensionality reduction, it may condense the dataset into fewer dimensions to make the data easier to understand and visualize. The output helps gain insights by revealing data groupings and the underlying structure of the data set. The output isn’t a final solution but a representation of how the algorithm organizes and interprets the raw data.
- Feedback and optimization: The process doesn’t end with the initial output. Analysts review the results and may adjust parameters to improve the model’s performance. For example, they might refine the number of clusters used in a clustering algorithm or modify metrics to better capture relationships in the data. This iterative process ensures that the unsupervised learning model generates more meaningful and accurate insights, which can then inform better decision-making. Analysts might also interpret the results to extract actionable insights, like identifying target audiences for a marketing campaign or detecting potential outliers that signal fraud.
Types of unsupervised learning
Unsupervised machine learning uses a variety of approaches and techniques to analyze and interpret unlabeled data. Each method is tailored to different kinds of tasks and datasets, making it possible to uncover patterns, structures, and insights in diverse applications.
- Clustering algorithms: These are powerful unsupervised learning techniques for grouping similar data points into clusters based on shared characteristics. Clustering is widely used for tasks like customer segmentation, image analysis, and document categorization. K-means clustering, for instance, divides data into a specified number of clusters, with each cluster centered around a calculated “mean” point. This method is efficient but requires the user to define the number of clusters in advance. Another approach, hierarchical clustering, organizes data into a tree-like structure called a dendrogram. This cluster analysis method doesn’t require specifying the number of clusters up front and helps visualize how data points relate to one another at different levels of granularity.
- Dimensionality reduction: As datasets grow in size and complexity, analyzing them in their original data form can become unwieldy. Techniques like principal component analysis (PCA), factor analysis, and singular value decomposition (SVD) simplify the data by reducing the number of data inputs or features while retaining the most significant information. This not only aids in visualization but also speeds up computations, making analysis more efficient. For example, PCA might compress a dataset with hundreds of variables into just a few components that explain most of the variance, making it easier to interpret patterns and relationships.
- Association rule learning: This method focuses on identifying interesting relationships and association rules between variables in a dataset. The Apriori algorithm is a common technique used in this area. It discovers frequent item sets and generates rules about which items tend to appear together. These association rules are particularly valuable in retail, and ecommerce for analyzing shopping basket data to understand product pairings, such as customers frequently purchasing bread and butter together. These insights can be used to optimize marketing strategies and inventory management.
- Anomaly detection: Anomalies, or outliers, are data points that deviate significantly from the rest of the dataset. Unsupervised learning methods identify these irregularities, making them invaluable in fields like fraud detection, where unusual patterns in transaction data might signal fraudulent activity. Anomaly detection is also used in system monitoring to identify potential failures or unusual behaviors in machinery, networks, or processes. Algorithms analyze patterns and flag anything that doesn’t conform to the learned norms, providing early warnings for intervention.
- Generative models: These models aim to create new data based on the patterns observed in the input data. Examples include autoencoders and deep learning techniques. Generative models are used for tasks like image synthesis, where they can generate realistic-looking images, or in natural language processing (NLP) to create human-like text. These models don’t just analyze data — they learn to replicate and generate it, opening possibilities for creative applications like designing virtual environments or simulating realistic scenarios for training purposes.
The advantages of unsupervised machine learning
Unsupervised machine learning offers several significant benefits that make it a powerful tool for analyzing unlabeled data and discovering patterns that might not be immediately apparent. Here are its key advantages, explained in more detail:
- Exploration of large datasets: One of the biggest strengths of unsupervised learning is its ability to process vast amounts of data without needing predefined labels or categories. In scenarios where labeling data is impractical, such as when dealing with billions of data points, unsupervised methods can uncover hidden patterns and relationships that might otherwise go unnoticed. For example, in analyzing customer behaviors across a global ecommerce platform, unsupervised learning can group customers by their purchasing habits, providing valuable insights for marketing strategies.
- Flexibility with new data: Unsupervised learning methods excel at adapting to new data because they don’t rely on labeled examples for training. This makes them particularly well suited for evolving or dynamic tasks, such as detecting outliers in real-time transaction systems or clustering changing social media trends. Their adaptability ensures that models remain relevant even when datasets are updated or when new patterns emerge.
- Reduced overfitting: Supervised learning models can suffer from overfitting, where the model becomes so tailored to its training data that it doesn’t perform well on new data. Because unsupervised learning techniques aren’t bound to specific labels or outcomes and focus on the overall structure of the data, they generalize more effectively, making them better suited for analyzing real-world datasets that include variability and noise.
Real-world applications and use cases
Unsupervised machine learning is transforming industries by uncovering hidden patterns, enabling smarter decision-making, and optimizing processes. Its ability to analyze unlabeled data makes it a powerful tool for tackling complex challenges across a wide range of sectors. Here are some examples of how it’s revolutionizing various industries:
Retail and ecommerce
Unsupervised learning is widely used for customer segmentation, allowing businesses to group customers based on purchasing behavior, preferences, and demographics. This enables personalized product recommendations, targeted marketing, and optimized pricing strategies. For instance, an online retailer might use clustering algorithms to identify high-value customers or frequent shoppers and tailor exclusive deals to retain them. Additionally, unsupervised models support pattern recognition, helping businesses understand seasonal trends or popular product combinations.
Healthcare
In the healthcare industry, unsupervised learning helps cluster patient records to develop tailored treatment plans and identify similarities in symptoms or responses to medication. It’s also instrumental in anomaly detection, where it identifies irregularities in medical imaging data, such as early signs of diseases or abnormalities in scans. For example, unsupervised learning can assist radiologists by flagging potential issues in X-rays or MRIs, ensuring earlier interventions and better patient outcomes.
Finance
Unsupervised models play a crucial role in fraud detection, where they analyze transactional data to identify unusual spending patterns or account behaviors that may indicate fraudulent activities. For example, detecting outliers in credit card transactions can help flag unauthorized use in real time. Unsupervised learning also assists in risk assessment, grouping clients based on financial behavior to help banks and insurers make informed decisions about lending or coverage.
Natural language processing (NLP)
In NLP applications, unsupervised learning improves sentiment analysis, chatbots, and language translation. For instance, clustering words with similar meanings or analyzing text data helps build models that can understand context better. These advancements make chatbots more conversational and translation systems more accurate, enhancing user experiences in industries like customer support and global communication.
Manufacturing and logistics
In manufacturing, unsupervised learning is used for anomaly detection to monitor machinery and identify early signs of wear or failure. By detecting outliers in equipment performance data, companies can prevent costly downtime and ensure smoother operations. In logistics, clustering techniques optimize supply chain management by identifying patterns in delivery routes or customer demand, improving efficiency and reducing costs.
Marketing and advertising
Unsupervised learning enables pattern recognition and customer segmentation, allowing marketers to identify groups of customers with similar preferences or behaviors. This data-driven approach improves targeted advertising campaigns, ensuring that the right message reaches the right audience. For example, by analyzing browsing habits, a company can recommend products that align with individual customer interests, increasing the likelihood of a sale.
Education and learning platforms
Unsupervised learning helps educational institutions and e-learning platforms analyze student behavior and learning patterns. Clustering techniques can group students based on performance, engagement, or areas of struggle, enabling more personalized learning experiences. This approach ensures that resources are allocated effectively, benefiting both students and educators.
Cybersecurity
In the realm of cybersecurity, unsupervised learning is used for detecting unusual patterns in network traffic, flagging potential breaches or attacks. By identifying outliers in real-time data, these models enhance system security and ensure faster response times to potential threats.
Limitations of unsupervised learning
Unsupervised machine learning models, while powerful, come with several challenges that can complicate their implementation and the interpretation of results. These include:
- Lack of clear evaluation metrics: Unlike supervised learning, where accuracy or precision can be used to assess performance, unsupervised learning lacks predefined labels, making evaluation subjective. For example, determining whether clusters produced by a clustering algorithm like k-means clustering are meaningful often requires domain expertise or comparison with external data, which may not always be available.
- Difficulty in optimization: Many unsupervised learning techniques require decisions about parameters, such as the number of clusters or the appropriate clustering method to use. These decisions are often task-specific and can significantly influence the outcome. Trial and error, combined with experience, is usually required, making the process both time-consuming and inefficient.
- Ensuring meaningful results: Without labels, the model might group or reduce data in ways that don’t align with human intuition or the intended application. For instance, in a dimensionality reduction task, the resulting compressed data may lose critical information, impacting the usefulness of the results. Ensuring insights derived from unsupervised learning algorithms are actionable and relevant is an ongoing challenge.
- Dependence on data quality: The effectiveness of unsupervised learning relies heavily on the quality of the input data. Noisy, incomplete, or irrelevant data can mislead the algorithm, resulting in overfitting or erroneous patterns. Preprocessing and cleaning data are critical steps but add complexity to the workflow.
- Interpretability of results: The complexity of some models, such as those involving neural networks or generative models, can make it difficult to understand why the algorithm reached certain conclusions. This lack of transparency can hinder trust in the results and make it harder to derive actionable insights.
What are future trends for unsupervised machine learning?
The future of unsupervised learning is set to overcome current challenges and unlock new possibilities, driven by advances in machine learning and integration with other technologies. Key trends to watch include:
- Combining unsupervised machine learning with reinforcement and deep learning: Unsupervised learning is being integrated with reinforcement and deep learning methods, enabling solutions for more complex, multistep tasks. For instance, these systems can process large datasets, identify patterns, and refine decisions using feedback, with applications in robotics, autonomous systems, and real-time optimization.
- Improved Python libraries and tools: As data science grows, Python libraries are evolving to make unsupervised learning more user-friendly. Libraries like Scikit-learn, TensorFlow, and PyTorch are regularly updated with new features, algorithms, and better documentation, making it easier for professionals and beginners to experiment and apply these techniques.
- Better evaluation metrics: Researchers are developing improved ways to evaluate unsupervised learning models. These new metrics aim to reduce reliance on manual interpretation, making results more consistent, objective, and comparable across datasets.
- Automation of workflows: Automated machine learning (AutoML) is extending to include unsupervised learning algorithms. This helps users explore data, optimize parameters, and interpret results with minimal manual effort, making workflows faster and more scalable.
- Semi-supervised learning integration: Unsupervised learning is being combined with semi-supervised approaches, where a small amount of labeled data guides the training process. This hybrid method boosts accuracy and interpretability while keeping the flexibility of unsupervised learning.
- Expanding into new areas: As unsupervised learning advances, it is being applied to fields like natural language processing, synthetic data generation, and advanced NLP models. These innovations are transforming industries such as healthcare and design, enabling solutions that were once too complex to achieve.
Frequently Asked Questions
Techniques like dimensionality reduction, including Principal Component Analysis (PCA) or t-SNE, are used to simplify high-dimensional data while retaining key information for analysis.
Preprocessing, such as normalization, scaling, and noise removal, is critical to ensuring accurate and meaningful results from unsupervised learning models.
Yes, unsupervised learning can process real-time data, especially in applications like anomaly detection and dynamic clustering, though it may require optimized algorithms for faster performance.
Unsupervised learning identifies patterns in unlabeled data, while reinforcement learning involves decision-making based on feedback from actions within an environment to maximize rewards.
Ethical concerns include potential biases in clustering, unintended consequences from misinterpreted patterns, and data privacy issues when analyzing sensitive or personal information.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.
