
Vector search is a technique that uses vector embeddings to find similar data points, such as matching a user’s query to relevant documents.
Understanding Vector Embedding
Vector embedding is a key idea in artificial intelligence (AI) that helps machines understand and work with complex types of data. It involves turning different kinds of information — like words, pictures, sounds, or documents — into numbers called vectors. These vectors are carefully designed to capture important patterns and relationships in the data. By converting data into this numerical form, machines can recognize similarities, understand context, and make predictions. This representation of concrete data can capture abstract concepts, like semantic meaning, connotations, and context-dependent relationships between words and phrases. Vector embedding has become a foundation for many AI tools, helping them perform tasks like searching for information, recommending products, and translating languages with greater accuracy and understanding.
What is vector embedding, and what are vector representations?
Vector embedding is a way of turning data like words, pictures, or sounds into a set of numbers that can be understood and analyzed by computers. These sets of numbers, or vectors, exist in what’s called a multidimensional space. This space isn’t physical but rather a way to map relationships and patterns mathematically. Each piece of data is represented as a point in this space, and the distance between these points reflects how similar or related the data is. For instance, words with similar meanings, such as “worried” and “anxious,” are located close to each other. This is an example of word embeddings, where the vectors capture the relationships and context of words in a meaningful way.
What makes vector embedding so valuable is how it helps computers work with unstructured data. Unstructured data includes information that doesn’t fit into neat rows and columns, like free-form text, raw images, or audio data and recordings. For traditional computer systems, this kind of data is challenging to process because it lacks a predefined structure. However, vector embedding transforms it into a structured format that AI systems can use. By creating a numerical representation of unstructured data, vector embedding allows machines to find patterns, make predictions, and draw insights more effectively than older methods can. This approach is foundational to many advanced AI applications, making tasks like searching, analyzing, and categorizing data much more accurate and efficient.
How vector embedding works
Vector embedding is created through a combination of steps.
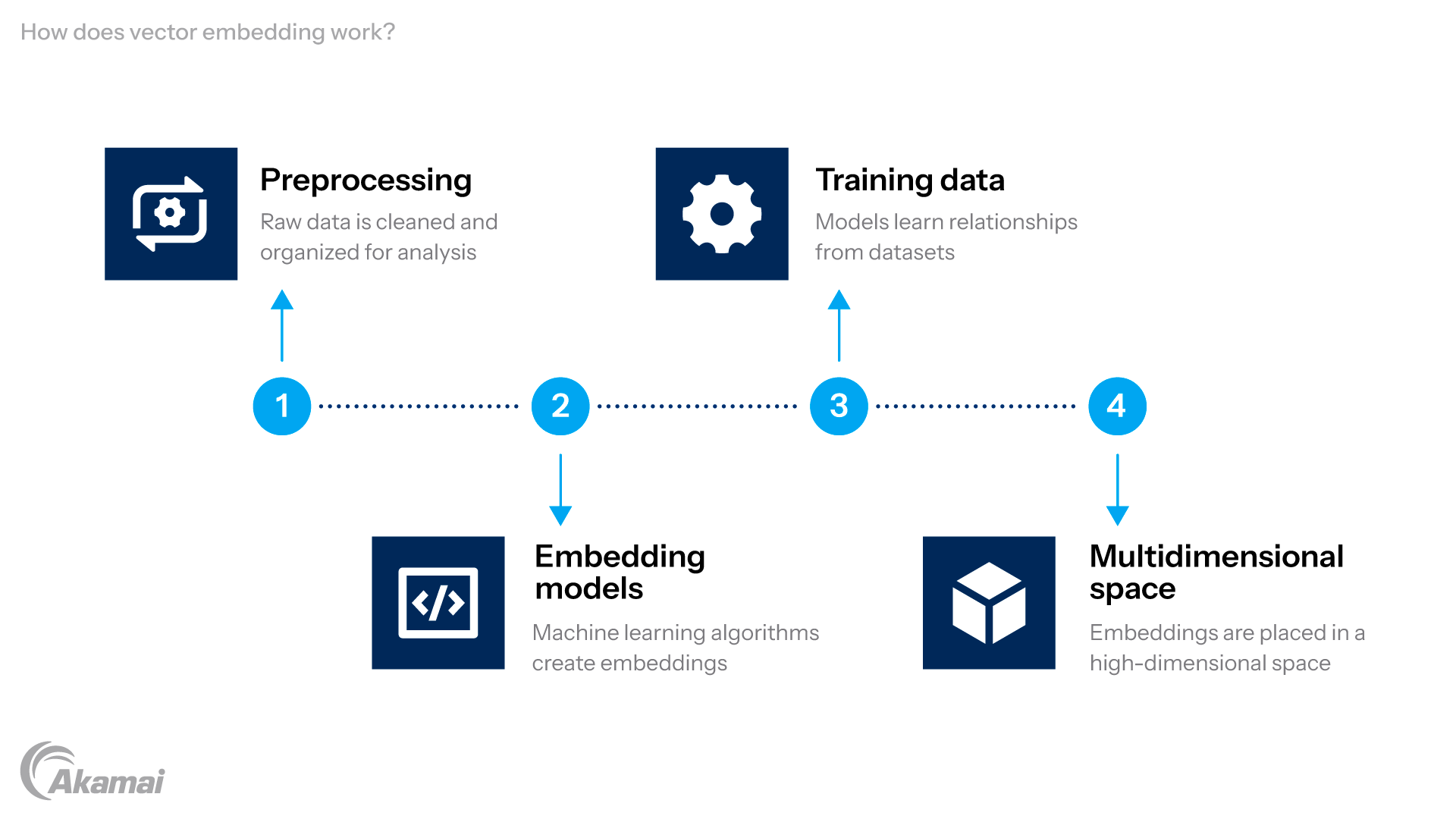
- Preprocessing: Data ingestion is the initial step, where raw data is collected and brought into the system for processing. After this, preparing data by cleaning, organizing, and transforming it makes it usable for further analysis. For example, text data might be tokenized, which means breaking down sentences into individual words or smaller units, like punctuation or subwords. Tokenization allows the system to focus on manageable pieces of information rather than trying to process entire sentences or paragraphs at once. Cleaning might also involve removing irrelevant symbols or correcting errors in the data.
- Embedding models: Once the data is prepared, machine learning models and algorithms are used to create embeddings. Neural network models are commonly used for creating vector embeddings, especially in deep learning applications. These models generate embeddings using APIs or specific tools. For example, models like word2vec, GloVe, or BERT analyze the data and map it into vectors. When working with image data, the output is called a feature vector, which numerically represents the image for tasks like similarity search. These models are trained on large datasets, which means they learn by analyzing massive amounts of data to uncover relationships, similarities, and patterns within the information.
- Training data: The embedding models rely on training data, which is the dataset they analyze to learn how to create meaningful embeddings. The process of creating vector embeddings is foundational for applications like semantic search and language models. For example, in natural language processing (NLP), a field focused on enabling computers to understand and interact with human language, embedding models can learn relationships between words. They may understand that “king” and “queen” are related because both represent royalty but differ due to gender. This learning process allows the model to create embeddings that reflect these nuanced relationships.
- Multidimensional space: The final step places the embeddings into a high-dimensional vector space, which is like a mathematical map where each data point is represented as a numerical vector with multiple coordinates. High-dimensional space isn’t something you can see physically, but it allows complex data to be represented mathematically. Each dimension represents a specific feature or characteristic of the data. For instance, text embeddings might include dimensions for tone, context, or word similarity. In this space, data points that are similar are placed closer together, while dissimilar points are farther apart. Mathematical operations, such as addition and subtraction, can be performed on these embeddings to explore relationships (e.g., “king − man + woman ≈ queen”). Embeddings represent data in a way that captures both semantic and structural features, enabling advanced tasks like similarity search and clustering.
Types of vector embedding
There are several types of vector embeddings that correspond to different categories of data and use cases. Each type serves a specific purpose and helps AI systems process and understand different data types effectively.
- Word embeddings: These embeddings represent individual words by analyzing their context and relationships to other words. For instance, models like word2vec use neural networks (a type of machine learning model inspired by the human brain) to create vectors that capture the meanings and relationships of words. Words with similar meanings, such as “happy” and “joyful,” will have vectors that are close to each other in the vector space. This type of embedding is essential for NLP tasks like language translation or information retrieval.
- Sentence embeddings: Unlike word embeddings, sentence embeddings represent entire sentences as single vectors. These are especially useful in tasks where understanding the overall meaning of a sentence is important, such as chatbots or sentiment analysis. For example, a chatbot can use sentence embeddings to interpret the intent behind a user’s message and provide an appropriate response. Advanced models like sentence-transformers are often used to create these embeddings, which help preserve the meaning and context of the entire sentence.
- Image embeddings: These embeddings convert visual data, like photographs or illustrations, into numerical vector representations. They are commonly used in applications such as image search, where users can find similar images by analyzing their embeddings, or in object recognition, where machines identify objects in an image. Tools like convolutional neural networks (CNNs), which are designed to process and analyze image data, are frequently used to generate image embeddings. These embeddings enable tasks like identifying a dog in a photo or grouping similar products in an ecommerce catalog.
- Graph embeddings: Graph embeddings represent the relationships between entities in a graph, such as people in a social network or nodes in a network of web pages. Each node in the graph is converted into a vector, capturing its connections and importance. This type of embedding is crucial for tasks like social network analysis, where insights about relationships between individuals are needed, or anomaly detection, where unusual patterns in a network, such as fraudulent transactions, are identified.
- Audio embeddings: These embeddings capture the unique features of sound, such as pitch, rhythm, and tone, and transform them into vectors. Applications include speech recognition, where spoken words are converted into text, and music classification, where songs are categorized by genre or mood. For example, a system might use audio embeddings to identify whether a sound is a dog barking or a person speaking.
- Document embeddings: Document embeddings go beyond word and sentence embeddings by representing an entire document as a single vector. This makes them highly useful for tasks like information retrieval, where systems need to find relevant documents based on user queries, or semantic search, which matches the meaning of a search term to the content of a document. By capturing the overall themes and structure of a document, these embeddings enable efficient and accurate document analysis.
The benefits of vector embedding for semantic similarity
Vector embedding provides numerous benefits that make it a cornerstone of modern artificial intelligence (AI) systems. These advantages improve how AI processes, understands, and uses data across a variety of applications.
- Efficiency: One of the most important advantages of vector embedding is its ability to simplify high-dimensional data (data with many variables) into smaller, more manageable vector representations. For example, a paragraph of text or a detailed image can be represented as a compact array of numbers. This transformation significantly reduces the amount of computational power needed to work with the data, making it easier and faster for systems to process and analyze large datasets. This efficiency is critical for real-world applications like recommendation systems or semantic search, where speed and responsiveness are essential.
- Semantic relationships: Vector embeddings are particularly powerful in capturing semantic meaning, which is the underlying relationship or context of the data. For instance, embeddings allow AI systems to recognize that “doctor” and “nurse” are related terms because they both belong to the medical field. This capability helps AI perform sophisticated tasks like language translation or machine translation, where understanding the relationships between words and phrases is crucial for accuracy. By preserving these semantic relationships, embeddings enable AI to deliver results that feel natural and intuitive.
- Flexibility: One of the standout features of vector embeddings is their versatility. They can represent many different types of data, from text data to images, audio, or graphs. This flexibility means that the same basic approach to creating embeddings can be applied across various domains. For example, text embeddings are used for search engines, while image embeddings power visual search tools. This adaptability makes vector embeddings a universal solution for handling diverse data in AI applications.
- Scalability: Embeddings are highly scalable, meaning they can handle increasing amounts of data and complexity without requiring significant changes to the underlying systems. Pretrained models, such as those developed by OpenAI, offer a practical way for developers to implement embeddings without needing to build their own large language models (LLMs). These pretrained models have already been trained on enormous datasets, saving time, resources, and computational power. For example, an ecommerce company can use embeddings from pretrained models to recommend products without having to train a model from scratch.
- Enhanced understanding of data points: Embeddings enable AI systems to recognize similar data points even when they aren’t explicitly labeled as such. This feature is particularly useful in applications like anomaly detection, where the system can identify unusual patterns or outliers in a dataset, or in recommendation systems, where products similar to a user’s preferences are suggested.
- Improved user experience: By leveraging vector embeddings, AI systems can deliver more personalized and relevant experiences. For instance, in semantic search, embeddings allow search engines to understand the intent behind a user’s query, providing results based on the semantic similarity of the search rather than just the keywords. Similarly, chatbots can use sentence embeddings to respond to user queries in a way that feels contextually accurate and helpful.
- Cost-effectiveness: By improving the efficiency of processing and reducing the need for custom-built systems, embeddings lower the overall cost of deploying AI solutions. Pretrained embeddings, in particular, make cutting-edge AI accessible to businesses and developers without requiring massive infrastructure investments.
Use cases and applications of vector embedding
Vector embeddings are versatile and play a vital role in various industries and research areas.
- Search engines: Search engines leverage vector search to improve how they retrieve information. Unlike traditional keyword-based searches, vector embeddings allow systems to understand the intent behind a user query, focusing on semantic meaning rather than just matching exact words. Word embedding techniques are used to represent words as dense vectors in a multidimensional space, helping search engines capture semantic relationships and improve the relevance of search results. This means a search for “places to eat near me” will return results for restaurants, cafes, or diners, even if those specific terms weren’t used in the content.
- Recommendation systems: Many ecommerce platforms, such as online retailers or streaming services, use embeddings to suggest products, movies, or music tailored to user preferences. For example, vector embeddings analyze the relationship between users’ past interactions and available options, recommending items that align with their interests. This personalization improves customer satisfaction and drives sales by connecting users with what they’re likely to enjoy.
- Chatbots: Advanced chatbots rely on embeddings, often created by models like sentence-transformers, to understand the meaning and context of user inputs. These embeddings allow chatbots to interpret questions and provide relevant, accurate answers. For instance, if a user asks, “What’s the weather like today?”, the embeddings help the bot recognize the intent to retrieve weather information, even if the phrasing varies.
- Image search: Platforms like photo libraries or ecommerce sites use image embeddings to find visually similar images. These embeddings convert visual features, like color, shape, or texture, into vectors that can be compared in a database. For example, if you upload a picture of a dress, the system can find similar dresses available for purchase, enhancing the shopping experience.
- Generative AI: Generative AI models such as GPT use embeddings to generate coherent and contextually relevant text. These embeddings enable the system to understand the relationships between words, sentences, and topics, allowing it to produce human-like responses in applications like content creation, chatbots, or virtual assistants. For instance, a model generating a story will rely on embeddings to maintain a logical flow and context throughout the narrative.
- Anomaly detection: Vector embeddings are used in fraud prevention and error detection by identifying patterns that deviate from the norm. For example, in financial systems, embeddings analyze transaction patterns to flag unusual behavior, such as unauthorized charges. By comparing new data points to existing patterns in a vector database, the system can quickly identify outliers.
- Language translation: In machine translation, embeddings play a key role in enabling accurate and context-aware conversions between languages. Models analyze the relationship between words and phrases across different languages, ensuring translations preserve meaning and intent. Embeddings help translate idiomatic expressions, such as “kick the bucket,” into culturally equivalent phrases in other languages.
Challenges and limitations
Vector embeddings are powerful tools, but they come with challenges that developers and researchers need to consider:
- High-dimensional space: Vector embeddings work in spaces with many dimensions, where each dimension represents a feature of the data. Managing and processing these spaces can be expensive, especially with large datasets. Systems need a lot of memory and processing power, which can slow down performance or increase costs for tasks like search engines or recommendation systems.
- Bias in training data: Embedding models learn patterns from data, and if the data has biases, the models may repeat or even exaggerate them. For instance, a model trained on biased text might associate certain jobs with specific genders, leading to unfair results. To avoid this, it’s important to carefully choose training data and use techniques to detect and reduce bias.
- Complexity: Using embeddings involves methods like cosine similarity (to measure how similar two vectors are) and indexing (to organize data for quick retrieval). Cosine distance is another commonly used metric for measuring the angle between two vectors, and is widely used in NLP and semantic similarity tasks. These methods can be hard to implement without specialized knowledge in AI and math. Mistakes in implementation can lead to slow systems or inaccurate results.
- Open source trade-offs: Open source tools make it easier to start using embeddings, but they often need customization to meet specific needs. For example, a general open source model might not handle specialized text or scale to millions of users. Customizing these tools takes time and advanced skills.
Future trends
The field of vector embeddings is evolving quickly, with exciting advancements ahead:
- Better deep learning models: Newer models like GPT and BERT are improving, providing more accurate and context-aware embeddings. This helps AI systems better understand complex data, improving tasks like natural language processing and semantic search. For example, these models can now better recognize subtle differences between similar phrases.
- Integration with RAG: Retrieval-augmented generation (RAG) combines embeddings with retrieval techniques to make AI smarter. It helps models pull relevant information from databases or documents and use it to give accurate, context-aware responses. This is especially useful for chatbots and question-answering systems.
- Faster indexing and similarity search: New algorithms are making indexing and similarity search quicker, which makes embeddings more scalable. These improvements enable real-time recommendations and instant search results, which are critical for systems with massive datasets, like search engines or ecommerce platforms.
- New applications: While embeddings are common for text and images, their use is expanding to areas like audio and graphs. For example, audio embeddings could improve speech recognition, and graph embeddings could help analyze social networks or detect fraud. These new uses will make embeddings even more versatile and open doors to innovation.
Frequently Asked Questions
Embeddings are created using embedding models trained on large datasets, often through algorithms like word2vec or deep learning techniques.
Yes, embeddings can represent various types of data, including text, images, audio, and graphs, making them versatile for different applications.
Developers often use tools like Python, pretrained models, and APIs to generate and work with embeddings. Open source libraries like sentence-transformers are also popular.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.
