
Akamai Inference Cloud delivers fast, reliable AI by running inference closer to users and data, not in distant centralized regions. Built on a massively distributed cloud and edge platform, it provides ultra-low latency, global scale, and access to specialized GPU resources exactly where they’re needed. Customers get centralized model management with distributed execution, reducing data movement, lowering cost, and improving privacy and compliance. With elastic capacity, high availability, and support for edge architectures, Akamai enables real-time AI experiences across agentic, industrial, scientific, visual, and enterprise workloads — without the complexity of building and operating global inference infrastructure.
What Is Distributed Cloud Inference?
Distributed cloud inference refers to the execution of AI and machine learning (ML) models (inference models, pretrained models, foundational models, LLMs) on distributed cloud servers to generate predictions or insights from input data. This process leverages the extensive computational resources and scalable infrastructure provided by cloud platforms. Unlike local or on-device inference — in which models operate directly on the end user’s hardware — cloud inference offloads the computational burden to powerful, specialized GPU servers. When a request for inference is initiated, data is transmitted to the cloud and processed by the deployed model, and the resulting prediction or output is returned to the requesting application or device. This paradigm enables complex models to be utilized without requiring significant local processing capabilities.
Advantages of distributed cloud inference
The adoption of distributed cloud and edge inference offers several distinct advantages, making it foundational to modern application architectures. By running inference closer to users and data sources, organizations can deliver faster responses, reduce data movement, and improve reliability while still benefiting from centralized control and elasticity. These benefits stem from the unique capabilities of distributed compute environments:
- Ultra-low latency: Cloud inferences run closer to users or devices, reducing round-trip times and enabling real-time experiences for agents, transactional systems, robotics, and interactive applications.
- Elastic global scalability: Distributed environments can scale dynamically based on traffic, provisioning resources during spikes and scaling down during low demand to maintain performance and efficiency.
- Cost efficiency (compute and data movement): Running inference near the data source reduces expensive data transfer and egress costs. Flexible consumption models further optimize spend by avoiding large upfront hardware investments.
- Centralized model management with distributed serving: Models can be centrally versioned, secured, and updated, while deployed across a global footprint to ensure consistency, lower latency, and better performance.
- Access to specialized hardware everywhere: Distributed cloud providers offer high-performance accelerators like GPUs close to end users, eliminating the need to build or maintain local ML infrastructure.
- Privacy, sovereignty, and compliance: Keeping inference closer to where data originates reduces cross-border data movement, simplifies adherence to data-residency requirements, and minimizes exposure risk.
- High availability and resiliency: Distributed cloud inference does not rely on a single region. Workloads can be routed around failures or congestion to maintain continuous operation.
- Hybrid and edge deployment alignment: Easily supports architectures where inference must run in the cloud or at the edge, enabling AI wherever data is generated or consumed.
Types of cloud inference deployments
Cloud inference can be implemented through various deployment models, each suited to different operational requirements and architectural preferences:
- Serverless inference: In this model, AI and ML models are deployed as functions that are invoked on demand. Cloud providers automatically manage the underlying infrastructure, scaling resources up and down seamlessly. This approach is highly cost-effective for intermittent workloads, as users only pay for the actual computation time.
- Containerized inference: Models are packaged within containers (e.g., Docker containers), which encapsulate the model, its dependencies, and the runtime environment. These containers can be deployed on managed container services (e.g., Kubernetes) within the cloud, offering portability, scalability, and consistent execution environments.
- Virtual machine (VM)–based inference: Models are deployed directly onto virtual machines configured with the necessary software and hardware specifications. This provides a high degree of control over the environment and is suitable for persistent workloads or specific compliance requirements, though it demands more manual resource management.
- Managed cloud inference services: Cloud providers (like Akamai Inference Cloud) offer specialized services that simplify the deployment, monitoring, and scaling of AI models. These services abstract away much of the underlying infrastructure complexity, providing a streamlined experience for developers.
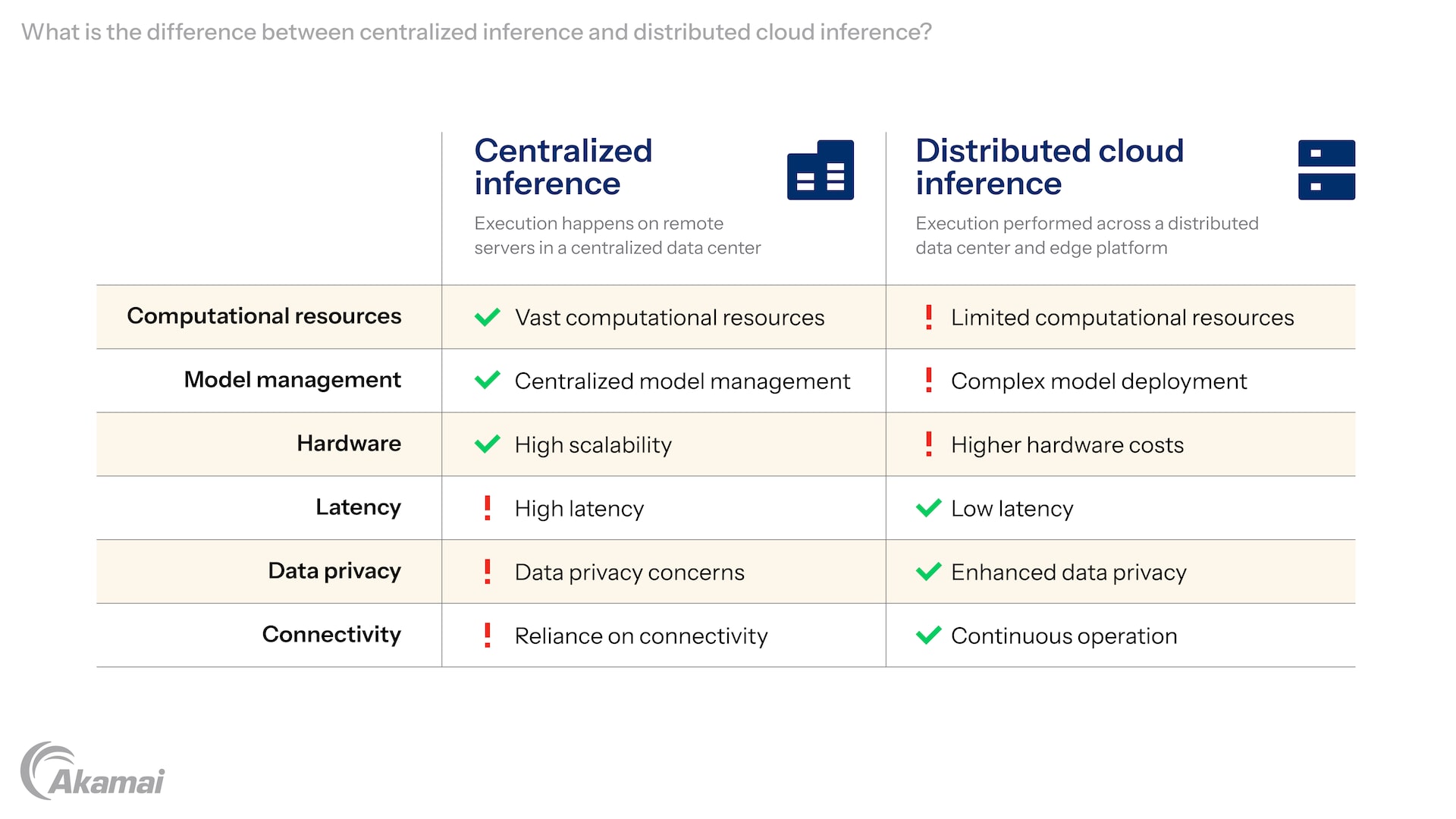
Centralized inference vs. distributed cloud inference
The distinction between a centralized cloud and distributed cloud inference lies primarily in the location where the AI/ML model inference execution occurs.
- Centralized cloud: As previously described, inference execution happens on remote servers in a centralized data center.
- Advantages: Access to vast computational resources, centralized model management, easier updates, and high scalability.
- Disadvantages: Latency introduced by network transmission, reliance on stable internet connectivity, and potential data privacy concerns due to data transfer.
- Distributed cloud inference: Inference execution is performed across a distributed data center and edge platform that brings artificial intelligence (AI) inference closer to end users (at the “edge” of the network).
- Advantages: Low latency, reduced bandwidth usage, enhanced data privacy (data remains local), and continuous operation even without internet connectivity.
- Disadvantages: Increased operational complexity in managing and orchestrating distributed inference across many locations. Can be overcome with a managed cloud.
The choice between centralized and distributed cloud inference often depends on specific application requirements, including latency tolerance, data privacy mandates, network availability, and computational demands.
Distributed cloud inference use cases
Cloud inference underpins a multitude of modern applications across diverse industries due to its flexibility and power:
- Agentic AI: Software agents perform autonomous reasoning and decision-making in real time by running inference close to users, enabling faster task execution and adaptive workflows.
- Industrial and physical AI: Factory, robotics, and safety systems react instantly to sensor inputs by processing inference at the edge, improving precision, reliability, and operational safety.
- Scientific computing: Researchers accelerate modeling and experimentation by running distributed inference to analyze complex phenomena, speeding discovery and reducing time to insight.
- Data analysis and simulation: Real-time inference supports rapid scenario modeling and analytics, helping organizations respond quickly to changing conditions without centralizing large datasets.
- Visual computing: Applications process images and video streams locally for object detection, scene analysis, and AR/VR rendering, improving responsiveness while reducing bandwidth usage.
- Enterprise applications: Business systems enhance productivity through fast, distributed inference powering recommendations, forecasting, fraud detection, and workflow automation.
Why is distributed cloud inference important for modern applications?
Cloud inference is critical for modern applications due to its ability to democratize access to advanced artificial intelligence and machine learning capabilities. It addresses several fundamental challenges faced by contemporary software development:
- Enabling complex AI features: By providing access to high-performance computing resources, cloud inference allows even resource-constrained applications to integrate sophisticated AI models that would otherwise be computationally infeasible on end devices. This accelerates innovation in AI-powered services.
- Facilitating rapid deployment and iteration: The managed services and scalable infrastructure of cloud platforms enable developers to deploy, test, and iterate on ML models much faster than with on-premises solutions. This agility is crucial in dynamic market environments.
- Supporting global scale and reach: Cloud inference ensures that applications can serve a global user base efficiently. Models can be accessed from anywhere, and cloud providers’ distributed infrastructure reduces latency for users across different geographic regions.
- Optimizing resource utilization: The elastic nature of cloud computing means resources are provisioned precisely when needed, preventing over-provisioning and underutilization, which are common issues with fixed on-premises hardware. This leads to better cost management and environmental sustainability.
- Driving data-driven decision-making: Cloud inference integrates seamlessly with other cloud data services, enabling comprehensive data pipelines. This facilitates informed, data-driven decision-making across various business functions.
Frequently Asked Questions
Cloud inference improves scalability through the inherent elasticity of cloud computing platforms. Cloud providers maintain vast pools of computational resources (CPUs, GPUs) that can be dynamically allocated. When the demand for inference requests increases, the cloud infrastructure automatically provisions additional instances of the AI/ML model or expands the allocated resources (e.g., more memory, higher CPU core count) to handle the increased load. Conversely, during periods of low demand, resources are scaled down, ensuring efficient utilization and cost optimization. This automatic adjustment prevents performance bottlenecks and ensures consistent service availability without manual intervention.
Securing cloud inference requires multiple layers, including:
- AI firewall: Protect AI-powered applications and large language models from novel threats, data leakage, and adversarial attacks through adaptive, real-time security at the edge to safeguard cloud inference workloads.
- Bot management: Detect, categorize, and mitigate malicious and unwanted bot traffic to safeguard web infrastructure and business processes that support cloud inference applications.
- WAF: Defend websites and applications against common and advanced web threats, including OWASP Top 10 attacks, at the edge to ensure secure delivery of cloud inference services.
- CNAPP: Gain a unified cloud native application protection platform, integrating workload, posture, and identity management to secure apps across hybrid and multicloud environments running inference pipelines.
- Application security posture management: Continuously monitor and improve the security posture of application code, APIs, and developer activities throughout the software development lifecycle for AI and cloud inference applications.
- API Security: Discover, monitor, and protect APIs from vulnerabilities, abuse, and data theft using behavioral analytics and threat detection to secure inference-driven API interactions.
- Data protection: Safeguard sensitive information through encryption, access controls, and compliance-driven security frameworks used in AI and cloud inference workflows.
- AI testing: Leverage AI-driven testing tools to automate, enhance, and validate application security, ensuring robust protection against emerging threats impacting cloud inference systems.
- Microsegmentation: Isolate workloads and restrict lateral movement within networks, enabling granular Zero Trust security policies across on-premises and cloud environments supporting distributed inference.
Cloud inference supports real-time applications by minimizing latency through optimized network infrastructure and high-performance computing resources. While network latency is an inherent factor, cloud providers deploy their data centers globally, allowing applications to utilize regions geographically closer to their users, thereby reducing transmission times. Furthermore, using specialized hardware like GPUs combined with highly optimized inference engines enables ML models to process input data and generate predictions with extremely low computational latency. Techniques such as caching frequent requests, preloading models into memory, and leveraging low-latency networking protocols also contribute to achieving real-time performance.
GPUs (graphics processing units) play a critical role in cloud inference by significantly accelerating the computational process. AI/ML models, particularly deep neural networks, involve extensive matrix multiplications and parallel computations. GPUs are architecturally designed with thousands of processing cores, making them exceptionally efficient at performing these parallel operations compared to traditional CPUs. In a cloud inference context, cloud providers offer instances equipped with high-performance GPUs, allowing for the rapid processing of large batches of input data or the execution of complex models with reduced latency. This accelerated processing capability is indispensable for applications requiring high throughput or low-latency responses, such as real-time video analysis or large-scale NLP tasks.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.
